
At Jetpack, dealing with different types of web threats and attacks is part of our routine. Most of the time, it ranges from collecting a malicious file and finding the attack vector, to providing assistance on restoring a website from the latest backup. But sometimes we enter a different dimension of really creative attacks, a dimension of inexplicable reinfections — we enter … the twilight zone.
Okay, I’m probably being over-dramatic, but bear with me as I set the scene for this mystery tale. Ready? Please join me on this trip to the realm of ghosts, spam, and search engines.
The malicious behavior
We found a website that was under a very interesting kind of attack. It first surfaced as an email sent by the Google Search Console: an uncommon URL (and a very suspicious-looking one at that, with a clickable URL inside) was listed as a top growing page.
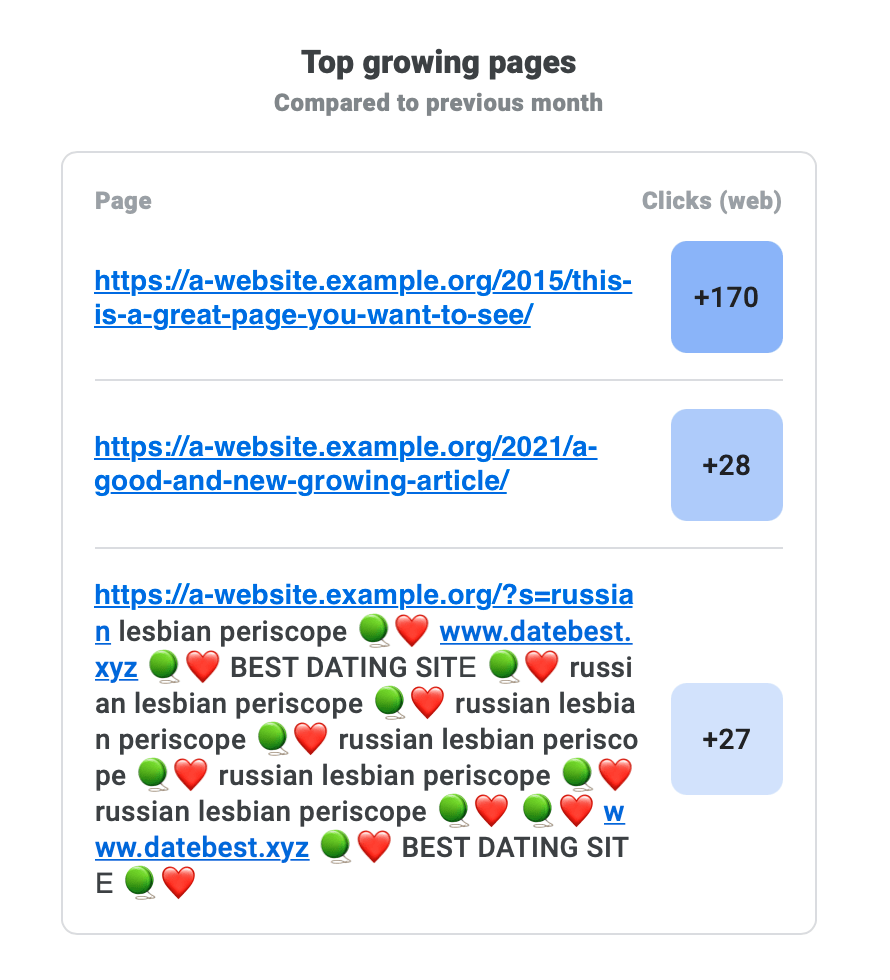
The website owner was a bit upset since behavior like this is often the result of an infection, but Jetpack hadn’t detected or warned them about anything. Plus, these pages didn’t even exist on the website when they checked, but were being indexed by Google anyway. Twilight zone intensifies.
As we checked for any suspicious files that Jetpack Scan may have missed (no security tool detects 100% of threats), things got even stranger. WordPress Core and plugins were intact: no injected file or scripts on the database. A couple of outdated plugins didn’t have any security fix on them, WordPress was one version behind (5.6), and the latest update didn’t list any big security fixes. There was nothing suspicious at all. No usual suspects, no evidence of attacks; not yet, anyway.
The next logical step is to check the access logs. Perhaps it could shed some light into this mystery. Would we find that we are facing a zero-day attack, or that we finally found a proof for the multiverse theory, and this website is only infected in Universe #1337? To the logs!


As you would expect: nothing strange, other than a bunch of requests to those spam pages as you can see on the screenshots. And they were all returning a `200 OK`. So, the page existed somewhere in the time and space continuum, or … wait a second … do you see it now?
All those pages were pointing to the same location: `/?s=`, meaning that search engines (the problem was noticed by Google, but the requests are coming from Bing) were indexing search result pages. And why is that? The crawler doesn’t perform searches on the page, as far as we know, right?
The indexing paradox
The basics of how a search engine works are fairly straightforward if you are in the website business. There’s a robot (or automated script) that crawls web pages, indexes its content, performs some magic, and stores the queryable resources somewhere in the cloud.
With that in mind, we dug the logs a little bit more to see if any of those requests had any other clue, like a referrer, but no luck at all. All logged requests were coming from search engines. Luckily, Google Search Console had one of the referring pages in one of the logs.

Now I think it’s time to switch our Twilight Zone hat for a CSI hat and dig up some website bones to put under the microscope.
For the trained eye, it’s easy to see that the referring page URL belonged to a compromised website; luckily, we have well-trained eyes! The `index.php` directory makes no sense and it was probably added to confuse the website owner. Next, it is followed by another random directory and a PHP file with a random name, which is probably a loader that is getting the final payload: the `cargese4/cca442201.htm`, which is also random. All of these are characteristics of a link-farm malware infection.
A quick search on Google to see what was indexed for the referring site confirmed that it was indeed infected and serving SEO spam for a while. The site is for a food company in India but offering deals on SUVs in Japan — yes, that’s spam.
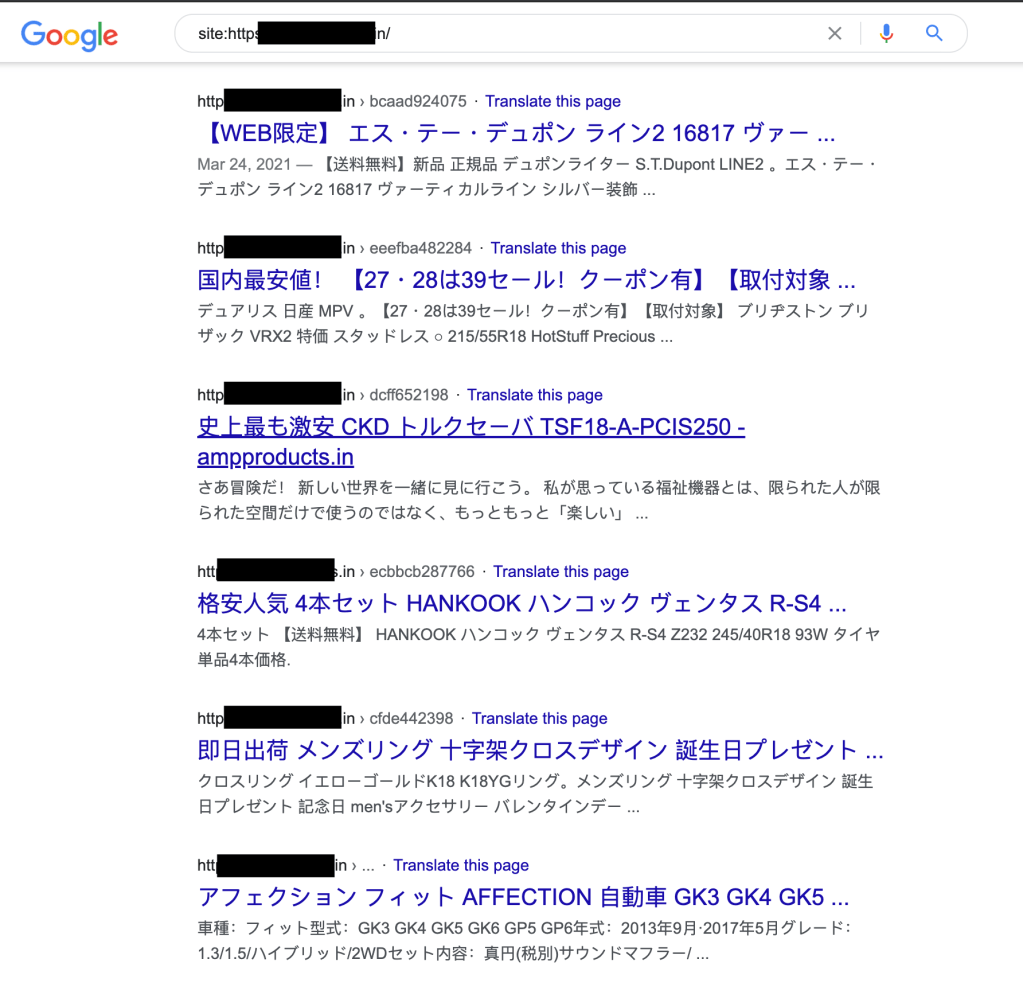
But, none of the results linked to our friend’s website, so I decided to find if other sites were affected by this same strange behavior.
In order to look for more victims of this spam attack we, for educational purposes only, used our Google-fu knowledge to craft a search query which would return sites ending with .edu, which had `/?s=` in the URL, and the word “buy” in the title. And we got 22 results. Which is enough for our hunt.

This is evidence that the reported site was not the only one affected; it seems to be a more widespread issue. We reflected on what could have made Google index those pages. How did the Googlebot reach them? Next step: backlink checkers.
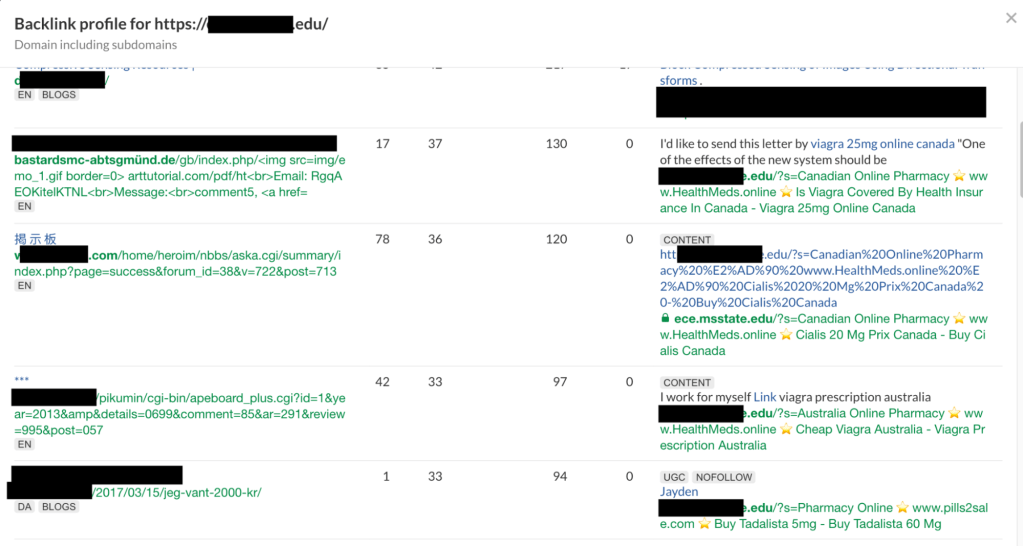
There are several online tools that provide reports on backlinks to websites; the one we used in this research was Ahrefs, but other tools may reach the same results. Some of the malicious search pages are listed in the results, confirming we were on the right path.
Selecting one of those websites to check what was going on, we saw almost 5,000 spam comments, as you can see in the next screenshot (they should check out Jetpack Anti-spam). Every comment was linking to a website search page with spam in the query.

Catching the white rabbit
As I mentioned before, search engine robots don’t perform queries on websites’ pages. But, if it finds a link to it, it’ll be followed. And if the page doesn’t tell the automated script that a particular page is not indexable, it’ll add it.

This is a clever method of “injecting” spam on a website for spamming search engine results and increasing site page rank through low-effort link farming.
Now that we understand the problem, how do we tell search engine bots to avoid following links to search pages (or just refuse to index them)? The best way would be to make a change to WordPress Core, which would help to protect the whole community (if you want to report a bug or want to contribute with the code, please join us).
In order to avoid some unnecessary rework, we checked the WordPress Core trac and found this issue that was solved on version 5.7 but unfortunately didn’t make it to the changelog as a security issue.
I’ll quote the author, who described the issue better than I could (thank you abagtcs for the report):
Web spammers have started to abuse search features of those sites by passing in spam terms and hostnames in hopes of boosting the search rankings of the spammers’ sites.
The spammers place these links in open wikis, blog comments, forums, and other link farms, relying upon search engines crawling their links, and then visiting and indexing the resulting search results pages with spammy content.
This attack is surprisingly quite widespread, affecting many websites around the world. Though some CMS’ and sites powered by custom-written code may be vulnerable to this technique, based on preliminary investigation, it appears that — at least in the .edu space — the most targeted web platform by far is WordPress.”
This isn’t surprising when more than 41% of the biggest sites on the web are WordPress sites.
Closing the case
There are some good lessons to be learned from this incident:
- The URL presented on Top Growing Pages is not well sanitized, so the spam URLs you see separated by emojis are actually directly clickable (hi Google friends, that’s on you 😉 ); unaware users could click on them and access unwanted content.
- Some tweaks are needed by Google to avoid indexing clearly spammy pages. Based on the tool report, some clear pages were crawled and not indexed, while spam was added.
- Attackers will leverage even the smallest opening on your system and we must be vigilant at all times.
- Always listen to people and understand their problems. If we only checked the logs from our own tools, we wouldn’t be aware of this issue or be able to help to fix their site.
- Keep your software up to date. Always.
At Jetpack, we work hard to make sure your websites are protected from these types of vulnerabilities. To stay one step ahead of any new threats, check out Jetpack Scan, which includes security scanning and automated malware removal.
And a hat tip to Erin Casali for highlighting this issue and helping with the investigation.
